
Detecting Fraud
This research aims to combine oversampling techniques and sparsity constraints to effectively detect and mitigate fraudulent activities, even in the face of imbalanced datasets.
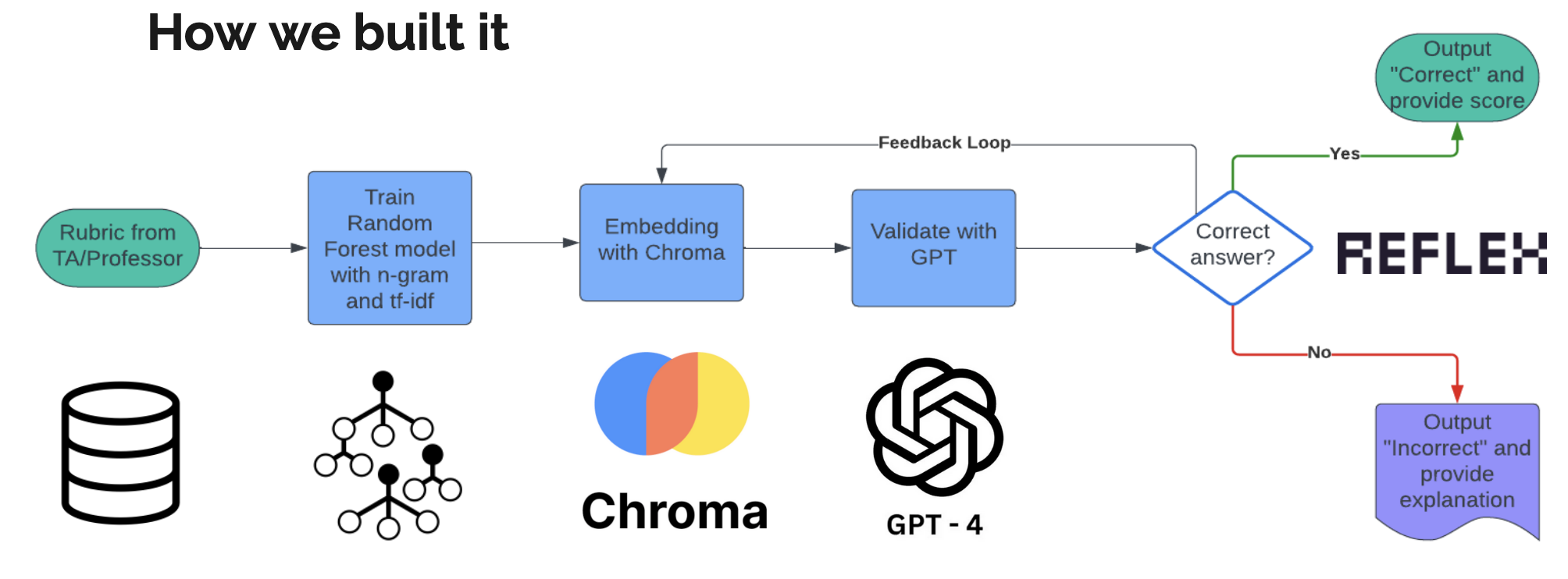
AutoScore
AutoScore aims to simplify the free response grading pipeline by analyzing the similarity to teacher-provided answers and using GPT to provide quick feedback for students. We utilize ChromaDB to handle vector database operations, GPT-4 to provide feedback, and Reflex for a front-end, full-stack solution.
GNN Long Range Interactions
This is a comparative analysis of baseline GNNs such as GCN, GIN, and GAT against the transformer-based model GraphGPS. These models are evaluated across the Cora, IMDB, and Enzymes datasets, as well as the PascalVOC-SP dataset from the Long Range Graph Benchmark to analyze their accuracy and provide insights into their performance.
Panama Papers
We utilize a dataset from ICIJ, which includes millions of leaked documents exposing personal financial information through offshore entities. Using XGBoost, we predict which entities are likely to be engaged in illegal activities. Our model intends to assist governments and NGOs in pinpointing entities most likely be involved in suspicious activities.

Suspicious Stock Trades
Are representatives from the state of Michigan better traders? Here, we conduct hypothesis testing on 14,000+ stock trade transactions to assess the trading skills of representatives. We also perform permutation testing to address data gaps and apply effective imputation techniques to handle incomplete data.

Homeless Center Expansion
We leverage data to aid the local homeless shelter's expansion by devising four key metrics and proposing a city to house 500+ homeless youth. Here, we present the findings with actionable insights to the homeless center's VP of Development and JPMC's data scientist panel.
Clothing Fit Recommender System
This project aims to develop and compare various machine learning approaches for predicting clothing ratings and fit. Leveraging interaction data and user/product features, this project delves into models such as linear regression, logistic regression, Jaccardian similarity, and TF-IDF.